host-extract is a little ruby script that tries to extract all IP/Host patterns in page response of a given URL and JavaScript/CSS files of that URL.
With it, you can quickly identify internal IPs/Hostnames, development IPs/ports, cdn, load balancers, additional attack entries related to your target that are revealed in inline js, css, html comment areas and js/css files.
This is unlike a web crawler which looks for new links only in HTML anchor tags or the like. Using that method you might miss many additional targets if you ever use such web crawler or other GUI-based tools that shows you your main target and its relationship with its linked sub/off-site domains.
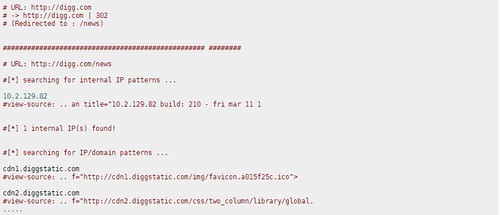
In some cases, host-extract may give you false positives when there are some words like – main-site_ver_10.2.1.3.swf. With the -v option, you can ask the tool to output html view-source snippets for each IP/Domain extracted. This will shorten your manual analysis time.
Usage
|
1 2 3 4 5 6 7 |
ruby host-extract.rb URL [option] Usage: host-extract [options] -a find all ip/host patterns -j scan all js files -c scan all css files -v append view-source html snippet for manual verification |
There are other tools that do similar things, some overlap, but nothing exactly like this. host-extract would be well combined with the following:
– wsScanner – Web Services Footprinting, Discovery, Enumeration, Scanning and Fuzzing tool
– theHarvester – Gather E-mail Accounts, Subdomains, Hosts, Employee Names – Information Gathering Tool
– Web-Sorrow v1.48 – Version Detection, CMS Identification, Enumeration & Server Scanning Tool
You can grab host-extract via SVN here:
|
1 |
svn checkout http://host-extract.googlecode.com/svn/trunk/ host-extract-read-only |
Or read more here.